Thanks to Eric Raymond, famous computer guru and leader of the open-source movement, at ESR, we can see what those sophisticated climate modelers were doing. They’ve found the code from the leaked files, and Eric’s comment is:
This isn’t just a smoking gun, it’s a siege cannon with the barrel still hot.
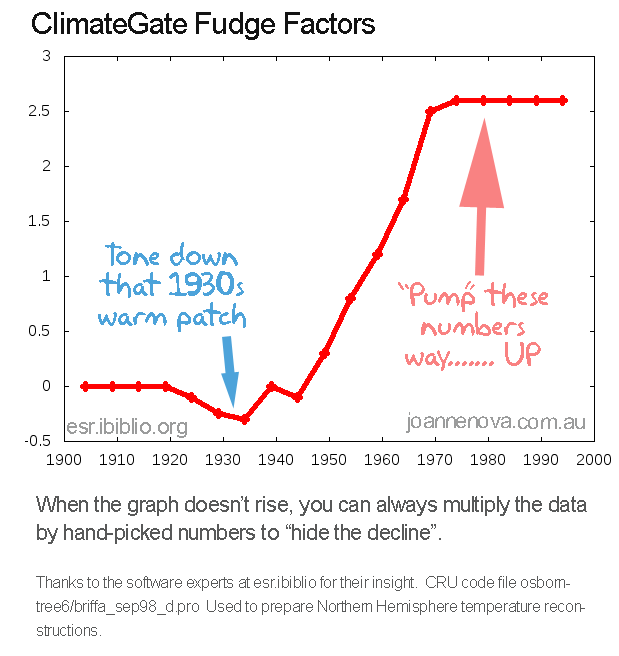
Here’s the code. The programmer has written in helpful notes that us non-programmers can understand, like this one: “Apply a very artificial correction for decline”. You get the feeling this climate programmer didn’t like pushing the data around so blatantly. Note the technical comment: “fudge factor”.
; Apply a VERY ARTIFICAL correction for decline!!
;
yrloc=[1400,findgen(19)*5.+1904]
valadj=[0.,0.,0.,0.,0.,-0.1,-0.25,-0.3,0.,- 0.1,0.3,0.8,1.2,1.7,2.5,2.6,2.6,$
2.6,2.6,2.6]*0.75 ; fudge factor
if n_elements(yrloc) ne n_elements(valadj) then message,’Oooops!’
The numbers in a row, in the [ ] brackets, are the numbers the data are to be altered by. If there were no adjustments, they’d all be zero. It’s obvious there is no attempt to treat all the data equally, or use a rigorous method to make adjustments. What could their reasons be?
East Anglia Data Adjustments
In 1900-1920: “All thermometers working accurately”.
In 1930: “Stock market crash and global depression causes artificial inflation in temperatures. Corrected, using inverted Dow Jones index until 1940”.
1940: “Due to WWII, briefly, thermometers work again”.
1945: “Artificial rise due to Nagasaki/Hiroshima effect. Compensated.”
1950 – 2000: “Quality control at thermometer factories must be going to pieces. Thermometers are just reading too low, and it kept getting worse until 1970. Instead of demanding the factories get it right, simply adjust the data. Still not enough. Quality control puts air-conditioning exhaust vents close to thermometers in the field, to further counteract apparent factory problem.”
Ladies and gentlemen, I’m seriously concerned. All along I’ve said the world was warming. Now I’m not so sure. How would we know? How does anyone know in the light of all that data fudging?
That hacker or leaker of info deserves glory and thanks.
Serious postscript: How can anyone defend this? These people work for a team that wants more of your money. Is this not evidence of criminal intent to deceive?









Anthropogenic Global Warming Virus Alert
Funny, sad and quite putrid all at the same time
20
None of us skeptics are surprised. the big question is, how do we get the man/woman in the burbs to see and understand this? HOW DO WE GET OUR POLICY MAKERS TO UNDERSTAND THIS?
I’ve got sore fingers from emailing senators.
20
Baa Humbug: HOW DO WE GET OUR POLICY MAKERS TO UNDERSTAND THIS?
That’s just it, the political elete already do understand this. They have known this from the get go. They were never concerned about the facts or reality. There interest was, is, and always will be the total and complete takeover of the economies of the world and the total enslavement of the population of the earth. That smaller such actions (USSR, China, Cambodia, North Korea, Vietnam et.al.) in the past has caused the collapse of national and regional economies and the deaths of hundreds of millions is music to their ears. All their pretty words and speeches to the contrary are simply smoke and mirrors to hide their real motivation from you. They consciously and willfully intend the consequences of their actions.
The what, why, how, and who is obvious. It’s what to do about it that is the challenge. If history is any guide (it almost always is), it’s going to get very ugly before it gets any better.
20
These fudge factors must be genuine. With the strict quality management systems in place at CRU, some top climate scientist must have derived the factors, another top climate scientist must have verified the factors and a third top climate scientist must have approved the factors. Isn’t that how it works?
20
We unfortunately have no forum except our own individual efforts to pound on our legislators. So we have to keep doing it.
The Global Warming Policy Foundation may help (http://www.thegwpf.org), but I’ve not had the chance to fully explore their site.
As for the joke at Copenhagen, there are enough nations unwilling to agree to any binding agreement to prevent anything from happening — except maybe hot air. China, India, Brazil and South Africa have formed an alliance with the intent of blocking any agreement, even to the point of walking out if necessary. So Copenhagen looks like another Kyoto. This is hopeful, very hopeful.
Nothing is guaranteed of course. But the more the thing can be delayed the more time is available for the truth to get out.
Our biggest enemy is the general public, most of whom hardly know how to spell the word science, much less how to tell if something is suspicious. Proof by authority works very well with those who have no means of defense against it. We must therefore try to educate. But it looks very difficult.
In our local paper a blogger made a great big deal of California’s own version of cap-and-trade — how wonderful that the City of Ventura is taking action to reduce its carbon footprint. I immediately responded by laying a little groundwork and asking for the evidence that CO2 is causing anything. I was challenged by some, but my insistence on seeing actual evidence has silenced them all so far. Even the blogger came back with proof by authority, which I then had an opportunity to explain and return the focus to the evidence. So Jo, your simple approach in The Skeptic’s Handbook has a lot of power. Is it enough? I don’t know. But the more we put the AGW people to this simple test the more chance of success we have.
20
Cooking the numbers and fudge.
These are a distraction. We still even with corrected numbers if there are any to correct, do not have proof of a link between CO2 and warming. We don’t even have warming.
10
Follow the money. The Big Banks, Big Energy, Hedge Funds have already begun investing in the latest round of corporate welfare. Cap and Trade “credits” is the New Las Vegas after the Housing bubble broke.
This is simply another opportunity for those on the ground floor to make millions, billions through taxes.
10
A commenter on WUWT has already discussed this with Gavin at RC. Gavin claims that this was never used in any published data set,but as a test of sensitivity for certain calculations to the presence of a post 1960 divergence.
These people will always have an excuse.
10
[…] This post was mentioned on Twitter by Cookingrecipe, imc00king. imc00king said: CRU Data-Cooking: Recipe Exposed! « JoNova: Thanks to Eric Raymond, famous computer guru and leader of the open-so… http://bit.ly/6Fzb0b […]
10
Phillip Bratby: wrote –
December 1st, 2009 at 1:24 am
These fudge factors must be genuine. With the strict quality management systems in place at CRU, some top climate scientist must have derived the factors, another top climate scientist must have verified the factors and a third top climate scientist must have approved the factors. Isn’t that how it works?
In good open science yes. But the Gavin discussion at RC contradicts your suggestion.
If you are right then what you suggest should of been done openly, with how each different correction was arrived at.
Gavin suggests these corrections were merely conveniently picked from the air to give the desired answer after the event.
Are you aware of Dr. Richard S Courtney’s 1999 paper regarding aerosol cooling factors in GCM climate modeling.
Courtney RS, „An assessment of validation experiments conducted on computer models of global climate using the general circulation model of the UK‟s Hadley Centre‟, Energy & Environment, Volume 10, Number 5, pp. 491-502, September 1999.
Richard S Courtney sums up what the paper says briefly with this recent excerpt from a posting at globalwarmingskeptics.info
specifically in this thread,
http://www.politicaldivide.info/globalwarmingskeptics.info/forums/index.php/topic,286.0.html
” My 1999 paper reports that the Hadley Centre GCM showed an unrealistic high warming trend over the twentieth century and a cooling effect was added to overcome this drift. The cooling was assumed to be a result of anthropogenic aerosol. So, cooling was input to the GCM to match the geographical distribution of the aerosol. And the total magnitude of the cooling was input to correct for the model drift: this was reasonable because the actual magnitude of the aerosol cooling effect is not known. This was a reasonable model test. If the drift were a result of aerosol cooling then the geographical pattern of warming over the twentieth century indicated by the model would match observations. However, the output of this model test provided a pattern of geographic variation in the warming that was very different from observations;
e.g. the model predicted most cooling where most warming was observed. This proved that the aerosol cooling was not the cause – or at least not the major cause – of the model drift. The Hadley Centre overcame this unfortunate result by reporting the agreement of the global average temperature rise with observations. But THIS AGREEMENT WAS FIXED AS AN INPUT TO THE TEST! It was fixed by adjusting the degree of input cooling to make it fit! However, this use of supposed ‘aerosol cooling’ to compensate for the model drift means that any input reduction to anthropogenic aerosol cooling must result in the model providing drift which is wrongly indicated as global warming. In any other branch of science this ‘aerosol cooling’ fix would be considered to be incompetence at best and fraud at worst Importantly, this one fact alone proves – beyond any possibility of doubt – that the climate models provide incorrect indications of global warming. My paper reported this in 1999, and no subsequent dispute of it has been published. ”
End of excerpt.
Whichever way round I look at this, “they” have a proven history of cooking the books.
It really is that simple, trying to turn round what is in the CRU “hacked” emails to any other explanation,
is being in denial of what they have done, what they are doing, and what they intend to continue doing.
It is already proven as a fact.
10
Henry (#6)… I agree entirely. We have to be careful to avoid getting caught up in focussing on the nitty-gritties of whether temperatures have increased or decreased, whether Arctic ice has increased or decreased, whether polar bears can swim, etc, etc. When you get to the end of those arguments, you are no further ahead. Whatever climate change is or isn’t happening, the relevant questions are what’s causing it, and what should be done about it.
20
It is difficult to be heard above the Lame Stream Media chorus. I really do think that the biggest argument for CAGW among the uninformed remains the hockey stick itself. I remember it well. The weather was hot, late summer or early fall, the blade of the hockey stick was red and it poked up past the top of the graph so you knew that was really,really hot. The stick was above ‘San Francisco Chronicle’ on the front page of the newspaper and I think most of us had the same reaction: “Oh shit!”
I thought at the time that Mr. Chen, the grad-assistant who ran the lab part of Physics 101 was still in charge of science. He made sure that everybody showed their work, “So someone else can do the same experiment and test your results.” Who could have imagined we had entered the era of post-modern science.
Serving humanity, Steve McIntyre has de-constructed the primary texts of CAGW but with Lame Stream Media doing the heavy lifting it has been difficult for the uninformed to hear what Steve and many others have said above the constant chant of the un-dead: “Peer review. Peer review. Peer review.”
That is what made the hockey stick look real and that is the mast they nailed their flag to, peer review and the appeal to authority. Now the peers have gotten bad reviews and their authority has been peeled. In the chill of what feels like winter already may this become the iconic moment that will sink the image of the hockey stick and destroy any claim it has on our consciousness.
20
Lionel (#3)… Wow! You certainly give politicians much more credit for intelligence than I do, Lionel. Whereas I agree that totalitarian global governance is a big part of the psychodynamics of what is happening, I really doubt very much that your average politician is even slightly aware of that.
10
Hi All,
“The Masses are more likely to believe a big lie than a small lie”
“The measure of a speech is not what the academics thought of it at the end but how the average person felt after the speech”
– Both quotes are not exact and both come from a historical figure who deserves no recognition (even though with these they were right).
Good work here. Now, I think what is necessary is to pull together a timeline of events – in graphical form – something clear with heaps of color and not too much wording. Have links to the in depth analysis.
We have seen the motive to decieve, we have seen the intent to deceieve, we have seen the methods and techniques used to decieve, we have seen the actual deceipt and we have now seen the massive efforts used to keep the deceipt (which are continuing with KRUDD using the term Denier yesterday.
Looks like game set and Match to me. Now it’s just a matter of distilling this all into single/double syllable english so the people quoting an inconvenient truth can understand it. Something New Idea would feel they could publish should be the goal.
Remember it is not their fault they were decieved, really, I mean who would have thought science had become so corrupt?
Average Joe bloggs isn’t going to care about who said what and when unless it’s some anorexic celeb, and they sure will fall asleep if the scientific method is mentioned.
We need a picture which is clear and easy to understand which shows what happenned, who was involved and the influence that had on say the IPCC/ KRUDD etc.
That’s my 2c worth
20
Derek: I was being sarcastic! Should have used a smilie.
10
I found this link on Junkscience.com. Penn State University has apparently begun an investigation into the activities of Michael Mann.
http://network.nationalpost.com/np/blogs/fpcomment/archive/2009/11/29/lawrence-solomon-climategate-the-investigations-begin.aspx
Those with dirty laundry are scrambling to come clean it seems. I’ve no idea what impact this will have on Copenhagen but it can’t be beneficial to the AGW crowd. I sure hope it gets as far as a good investigation into James Hansen.
10
Actually I think there should be a legal challenge to the “science”. I’d be happy to contribute towards it. Darn sight cheaper than an ETS will be.
10
My apologies Phillip, on the positive side, I hope I have helped (@ post 10) you nail your point (@ post 4).
BTW – A pdf I have recently posted elsewhere that hopefully nails climate modelling and it’s main assumption, + a little relevant history…
http://www.globalwarmingskeptics.info/forums/thread-309-page-1.html
The RSC quote is from the pdf, as “they” need to alter the cooling, because the assumed warming mechanism was producing too much heat,
to get the right answer, after the fact.
Literally the models told them what to find, and where and when to find it, so off “they” went to find it.
Temperature, Ozone, CO2, tree rings, you name it, “they” made sure they found the right amount in the right place, at the right time.
Except for the assumed heating mechanism – Quack, quack, ooooops…….
10
On the same day that the email hack was announced the AP published a long article with the latest disaster scenarios of doom for humankind unless we devolve to the 1850’s and give all our money to the U.N. The AP has pointedly refrained from any retraction or coverage of the AGW fraud the emails expose. Typical of the lamestream media
10
Has there been any more on the origin of the file collection? Was is supposed to be released under McIntyre’s FOAI request, or was it something put together by an insider to make a point. It seems that Mann et al would never authorize most of the emails and some of the documents. It’s almost like the lawyers said “Put together everything you have and we’ll decide what to send”, and this is what resulted. No wonder they tried so hard to get the request denied. Of course, they didn’t count on someone with a conscience recognizing what this was and making sure it was made public.
The hacker idea is clearly bogus. It would have taken weeks of root access searching across a network of machines in order to produce such a targeted data set. Even if you were an insider and knew the system, it would take days. I doubt that their network is that vulnerable and that they clearly produced the file. It would be interesting if they disclosed what they prepared the file for.
I can verify at least one piece of data, which is that RC is definitely in the business of censoring posts from skeptics. I’ve even had questions censored because the answer was inconsistent with AGW. In one exchange, Gavin admitted that his role was to promote only that science which supports AGW.
George
10
what is that written in? Is that “M”. (I smell the mumps)
{
For your newbs out there M is short for mumps. Which is very funny and suiting for this story. It is such a terrrible language that hidding a fuduge factor in it could be easily missed. Or more likey abandoned and untouched for 20+ years.
}
10
If you were really a skeptic you would know the answer. Next time instead of emailing them with your thumbs try sending them lots of money over a long period of time. They already know and they don’t care.
10
[…] Hinterlasse einen Kommentar » CLIMATEGATE – Forget the emails, the real evidence of Climategate is in the code […]
10
“Forget the emails, the real evidence of Climategate is in the code…”
Yes, and for anyone who hasn’t seen the garbled mishmash of what passes for CRU’s code that they use as the basis for their catastrophic AGW conclusion, see here:
http://www.anenglishmanscastle.com/HARRY_READ_ME.txt
That code and the comments by those trying to bludgeon the data into something that supports the CRU’s catastrophic AGW conjecture makes clear that Phil Jones, Tom Wigley, Michael Mann, Keith Briffa and their clique of enablers have an impossible job. Just look at the code they use as the basis for their CO2 = CAGW scare, and the interspersed comments complaining that the code is an unsalvageable mess. None of this can reasonably be called science, and that is why they repeatedly refused legitimate FOIA requests.
Also, look at just a partial list of climate grant recipients, and the money funneled to them by various Trusts, Foundations, quangos and foreign governments that have a strong AGW agenda:
http://www.cru.uea.ac.uk/cru/research/grants.htm
Over the past decade Phil Jones alone has collected more than $22 million [USD] from groups with an AGW agenda. He knows that if he did not give his benefactors the results they paid for, others would get future grants. So Michael Mann, Phil Jones and his cohorts at CRU [and no doubt plenty of politicians] give them the AGW story they want, and the grant money keeps flowing into into their pockets. But the taxpayers, who pay for honest, unbiased scientific research by CRU and Michael Mann, are being defrauded.
10
just investigate who would make most of money on cap & trade and you get a straight answer for what is really going on and how “real” it could be…
[tip: it starts with a big G and it comes in two words, the initial of the second is S, and most of US governments since decades are funded and controlled by their alumnis]
10
Lionel Griffith writes above “HOW DO WE GET OUR POLICY MAKERS TO UNDERSTAND THIS?”
Don’t worry, Lionel. At least here in the US, enough of them do understand what’s really going on here that “cap & trade” legislation is now dead for the foreseeable future and quite possibly for good. That’s what’s really the most important thing. The Republicans have always been pretty much 100% against cap & trade. But in the wake of the damning revelations coming out of the CRU at East Anglia, there’s no way that the dozens of conservative and moderate Democrats who may have previously been on the fence will support it.
In fact, I doubt we hear too much about it from liberal moonbats like Nancy Pelosi and Barbara Boxer. They may be idiots, but they also have to sense that “cap & trade” is now a political non-starter here in the US.
10
Friends:
A week ago in another thread I suggested that Phil Jones is likely to be a scapegoat. He has now been suspended pending investigation.
I see no reason to change my opinion.
Richard
10
[…] here: CRU Data-Cooking: Recipe Exposed! « JoNova By admin | category: cooking | tags: cooking, imc00king-imc00king, more-pounds, raymond, […]
10
Here is a great piece by Tim Lambert at Deltoid looking at the code that Eric Raymond is so excited about.
http://scienceblogs.com/deltoid/2009/12/quote_mining_code.php#more
and of course Tim is very much qualified to comment on this although some think he is maybe not on climate change (although they approve of Steve M?)
Of course this will be dismissed, but a skeptic would see that this piece by Raymond is yet another poorly reviewed grasp at anything opposed to AGW.
10
Matt, I had a bit of a read on Deltoid and while I appreciate that the particular piece of code does not deliver a “smoking gun” demonstration of fraud, it is part of a larger picture that demonstrates blatant disregard of the truth. We are not actually searching for proof of CRU fraud, we are searching for whether or not CO2 causes Global Warming, and the CRU emails are nothing more than a weighting factor applied to the strength of their evidence.
What matters is: was their methodology scientific? Were they meticulous in their process, and honest in their publication? Every piece of evidence answers “no” to these questions, including their reluctance to allow independent audit of their work, and the general attitude of carelessness when it comes to detailed documentation and reproducibility.
From the comment on Deltoid by Michael Ralston:
This very much summarises the attitude of many researchers and I’ll point out exactly why it is wrong. There are excellent reasons to keep your code clean in both an industrial context and in a research context. List of what comes to mind:
* Neater code is more likely to be correct because the fundamental basis of writing correct code is being organised.
* Publication of a theory (in a research context) is a matter of communication. The purpose is to convey your ideas to the reader in as complete and accurate form as possible. Publishing easily readable code is a totally necessary part of that transfer of ideas.
* Science is about repeatability, which means the researcher must be in a position where he can go back years later and re-examine previous trials. This requires the code be well commented and supported by documentation.
In particular the “all that matters is the output” comment totally sets my teeth on edge. This represents an all too common haphazard attitude to reliability that has given the entire software industry a bad name. I regularly hear things like, “It works, what’s the problem?” and of course the question is, “Will it still be working at 03:00 this morning?” and in particular, “Are you sure it will still be working?”
What I know from experience is that there is no technology that can fully be depended on, it will break, the question is when, not if. This is why software needs to check input bounds, report errors and warnings, shutdown cleanly and predictably, and be able to deliver internal justification for whatever outcome it produces. I want systems that I can easily fault-find when they go wrong, so I can rapidly get them running again. I want fallback options. Garbage In, Diagnostics Out.
A few comments above from Harald Korneliussen:
What is this guy advocating? Not doing the tests? Shouldn’t have to check the config file? Not bothering to read up on what a script is designed to do before you run it?
There is at least some evidence that the early Arian-5 launch was self-destructed because of a versioning error where some config from the Arian-4 control system got into the Arian-5 controller. The A4 engine was smaller than the A5 engine and the controller had reasonable bounds checking to determine whether everything was operating within a well behaved range. Reasonable bounds for A5 were substantially different and getting these details right really does matter.
You could just take away the reasonable bounds checking and hope for the best but when you are setting fire to a large tub of explosive chemicals you want a controller that is not going to knock a crater into a populated area. The likes of Korneliussen simply don’t have the same concept of embarrassment that rocket engineers do.
These people talk about the “Precautionary Principle” but they don’t take basic precautions with their code and their data, and they lambast those who do.
I suggest you have a bit of a review of archival software and versioning systems in the computer industry. I’m familiar with the history of SCCS, RCS, CVS, CVS, Bitkeeper and GIT. That particular lineage is mostly associated with the Open Source industry but actually there are many others from different corners of the industry. You might wonder why computer nerds spend so much time and effort with stupid archival and versioning systems that don’t actually deliver any additional results. The reason is because those small versioning differences really do matter!
The CRU emails made it clear that their system of archives and versioning was shot to pieces. Commentators on Deltoid and elsewhere can speculate about where a particular piece of code was used, or which version was associated with which publication… the point is that we will never know. The original authors will never know. Quite possibly some other version of the code produced that published output and this particular version was short lived and never properly archived. This is not science, it is shooting craps.
Maybe for purpose of a criminal investigation or a political campaign it would matter to find the difference between deliberate intent to defraud and accidental incompetence — from a scientific perspective is makes not one jot of difference, wrong is wrong. If you can’t provide clear provenance for your measurements from first principles to final thesis then the outcome is not worth diddly. Sorry if that’s a bit difficult, perhaps consider pastry decoration.
10
Tel the point is that that piece of code was put forward as THE SMOKING HOWITZER CANON FROM HELL (paraphrase). Realistically all that can be done is explain why people who show things like this to be the last straw on the camel are simply wrong.
As for general research code… well I’m not a computer programmer/software engineer, but I think that while sloppy code is undesirable it does not make it wrong, but for sure it would be great if all code for publication in peer review had to be independently peer-reviewed and tidied up. It is easy for hard core computer engineer types to be scathing, but that is their bread and butter compared to this where it is a useful tool that they are pretty much self trained and unregulated in. I’m not defending, just saying it as it most likely is. Some folks are amazing at documentation and clean succinct code, others are not, that is just people for you.
Anyway I note you say that you are not seeking proof of CRU fraud… that is great but I think it is pretty easy to see from the blogosphere that people are doing exactly that to somehoe demonstrate fraud, and that that debunks the AG science.
Anyway I enjoy your posts and very often agree wholeheartedly… and I can’t say that for many here so cheers for your efforts. I don;t sense much ideology driven blindness. So we disagree on the final conclusion… ahh well.
10
In the end it comes down to a simple statement of fact.
CO2 has a nil effect upon temperatures in our planets open-to-space atmosphere,
there is no so called “greenhouse effect”.
However it has been dressed up, AGW is imaginary,
whoever or whenever the codes were invented, and,
whoever or whenever altered the codes used.
Raw data always trumps everything else.
We are just beginning to realise how little raw data there actually is.
Virtually none.
10
[…] More here […]
10
Matt, Tel,
I am a software engineer, so I can speak here. I’ve seen these emails, including the code snippets in which we find the following comment.
; Apply a VERY ARTIFICAL [sic] correction for decline!!
I’ve seen the following code that would use the modified data but is now commented out. But the fact that the numbers were cooked to hide what they didn’t want anyone to see is, in fact, a smoking gun. Hell, it’s an atomic bomb going off in their lap. Why? Because those statements now commented out were originally not commented out. Otherwise why bother to cook the numbers? There is a clear intent to deceive here. Does it matter who was to be deceived? Lie to me once and then try to convince me that I should believe you again. Just try it.
This is about dishonesty, not sloppy code or anything else. The comment gives them away. The programmer even added emphasis to what was going on with a pair of exclamation marks. They can’t stand up anymore in the company of honest men.
I deal with complex software running a very complicated and expensive piece of laboratory equipment. What do you think would happen if my employer found that I had written code to manipulate data to make it look a certain way when in fact it was not that way?
A lie is a lie! You cannot spin it any other way.
It seems likely to me that the researchers themselves or some assistant wrote the programming for all their modeling and data manipulation. This is the usual practice in general and there’s no reason to believe they needed a software engineer to do the work for them.
10
Mattb @ 31: …well I’m not a computer programmer/software engineer, but I think that while sloppy code is undesirable it does not make it wrong….
Well I AM a computer programmer/software engineer and have been for over 40 years. I will tell you that sloppy code IS wrong. First, because you can’t be sure that it does only and exactly what you say its supposed to do. Second, because you can’t test it to verify that it only does what you say its suppose to do. That is largely because you can’t know how to test it. Thirdly, its sloppy BECAUSE you don’t know exactly what or how its to do what you say its supposed to do, you were incompetent, or you were careless. Hence, sloppy code is prima facie WRONG! If its “right”, its right by accident and you have no way of knowing that it is right.
Now for clean, well structured, and well documented code. It may do exactly and only what you say it does. You may be able to demonstrate that it in fact only does what you say it does. However, this has two critical problems. First, it is impossible to test software exhaustively for every possible combination and permutation of input conditions. There is simply not enough time left to do it before the sun burns out AND it would be outrageously costly and impractical to attempt to do it. The BEST you can do is test for proper behavior for classes of input conditions. Secondly, it may be that even though your software is doing exactly what you say it is supposed to do, THAT may not be the correct thing to do. It is very likely that you have solved the wrong problem, for the wrong context, at the wrong time. Now, this does not mean the code is wrong. It merely means that it is damn difficult to know that it is right and still painfully easy for it to be wrong.
Putting the above in the context of justifying transforming the economies of the earth into a pre-industrial hand to mouth existence based upon output of monumentally sloppy code, one could clearly say the plan is monumentally stupid with monumentally disastrous results the only outcome.
20
I’ve been writing SW for decades and the conclusion I get from examining the CRU code is that it’s crap. If someone was working for me and was producing stuff like this, I would fire them.
Much of my coding has been related to scientific modeling, which 25 years ago I was writing in F77. I’ve been writing this stuff in C and C++ for almost 20 years because modern programming languages are far more productive. Simply the fact that these guys are still stuck in Fortran tells me that if they haven’t spent the effort to migrate to a more modern language, they certainly haven’t spent the time to invest in revision control and modern validation methods.
The fact that trillions of dollars are dependent on the veracity of this code is scary, appalling, insane, irresponsible and even dangerous. At least it seems that the public is starting to see the big picture.
Matt: The reason the blogosphere is heating up about this is because of decades of stonewalling from the likes of CRU. I agree that there’s no single email or piece of code which is the definitive smoking gun. To take a page from the AGW playbook, while there’s no definitive proof/smoking gun, it’s the net result of a lot of little things that convinces me.
I don’t know if you’ve actually looked at the emails. It’s not just a small sample of stale, out of context messages. While the emails go back more than 10 years, most are from 2004 on, documenting multiple, complete email threads per week, including most, if not all, relevant email context. This is a statistically significant sample, in fact, more so than any of the sampled data sequences used for temperature reconstructions.
George
10
cp2isnotevil,
I would say you are heaping praise on the CRU code. The code so far from being as good as crap that you have to use a logarithmic scale to measure the difference.
It is possible to write good code in Fortran. I started with Fortran II in 1965 and stopped using it with Fortran 77. I found that it was/is so very easy to write crappy code in Fortran that almost all Fortran code is crap or worse. Its mostly because the bulk of the Fortran code was written by people who, after making a Hello World program work, thought they were Fortran programmers.
I have been writing code in C since the mid 1980’s. Interestingly, its even easier to write crappy code in C than in Fortran. See nearly any unix program or unix itself for a case in point. C++ simply takes the ease of writing crappy code to new heights. See every MFC based program for another case in point. The bottom line is that its damn difficult to write good code IN ANY LANGUAGE. That is why we have well millions man years of effort dumped into software and almost all of it is no longer in use. It was crap when it was new.
Check out what it took to write the very high reliability code for the Space Shuttle: fifteen years and 275 people and even it had some serious problems.
In short, IBM/Loral maintains approximately 2 million lines of code for NASA’s space shuttle flight control system. The continually evolving requirements of NASA’s spaceflight program result in an evolving software system: the software for each shuttle mission flown is a composite of code that has been implemented incrementally over 15 years. At any given time, there is a subset of the original code that has never been changed, code that was sequentially added in each update, and new code pertaining to the current release. Approximately 275 people support the space shuttle software development effort.
From: http://www.nap.edu/openbook.php?record_id=5018&page=9
Like I said. Writing really good code is not easy, its not cheap, and it cannot be done by novices. It also cannot be done by trained professionals who have idiot managers and arrogant PHD’s dictating the what, why, how, when, where, and the tools to be used to get the job done while changing the all but non-existent specification without notice. See the Harry read me file for a case in point. I know whereof I speak. I have been there, done that, and work for myself by myself because of that experience.
20
Lionell,
Yes, I certainly agree that it’s easier to write crappy code than good code in any language. The README file was one of the first I looked at when I downloaded the package. It’s quite revealing.
What’s also interesting is the many variants of some of the code, written by different people. It’s almost like there was a contest to see who could match the data the best with the least obvious fudge factors.
There are many versions of the data in the zip file and many variations of the processing code. I wonder if anyone will ever find the combination that actually produced the graphs in the IPCC reports or if that combination even exists.
George
10
Lionell/c02isnotevil,
RE: crap code. Agree, totally. Having worked in the SW Engineering field for more than a decade and I have seen some of the most shocking things even a lay person would find hard to believe.
Hence, why I was skeptical many years ago when I found out that their predictions were made based on Models – it’s a sure bet that the original coder for this model was probably some under graduate who would’ve done *exactly* what they were told. I’d bet their code wasn’t even peer reviewed.
Then poor Harry comes across it and figures out that everything is based on this. Gee it must have been so demoralizing to find you were working for the wrong team. Poor sod, but hey, we’ve all been there right?
There is only one solution to poor code I have found is economical. Rewrite it properly, don’t try and revive a crap codebase. Of course, politics get involved when you say things like that, and the CRU, like many academic institutions is largely a political one.
10
Apologies in advance – this is a long post and is OT!
All the talk of “crap code” is very interesting, and while I certainly agree that such a thing is not good, it’s perhaps more important to look at the overall process of modelling and compare climate models to what most people think of when they think of computer models – those done to engineering standard for public works projects, buildings, bridges, cars and so on. These are all very different animals to climate models. For situations where peoples lives and livelyhoods are at stake, any engineer that used a model that has not been verified and validated would be lucky to keep out of prison, even if no-one had been hurt – they would certainly have their license to practice engineering revoked at the very least. No climate model that I am aware of has been verified and validated. None. Ever. Every time I’ve asked people for such studies, I have not been shown where such data is, or even been told where I might start looking for it – even by such people is Gavin Schmidt, Eli Rabbet et al. IOW, people who claim good “inside” knowledge of such code.
So what is verification and validation? In simple terms, verification means that the program is checked to make sure it is calculating what the design specification says it should. For instance (and this is rather technical, but I have a “simple” answer as well), one step is convergence: that the discrete and continuous solutions to the (partial)differential equations converge. An example of this is the “pixelisation” filter in photoshop – apply it to an image and at “low” values, it looks the same but a little bit “blocky” or “blurry”. Apply it at “high” values, and there is a point where suddenly it no longer looks anything like the original image. We would say that below this point, we have convergence and above it, we do not. When we look at climate models, a great many use the 3d Navier-Stokes equations. In the published literature, the ONLY study that has investigated convergence in 3D N-S in the 40 odd years since it was first published (Ye et al) shows no convergence at any scale. This would tend to indicate that what these models produce is numerical noise and nowhere close to reality. That there are other papers (sorry, no cite) that suggest that changes in the “time step” of the models has a significant effect on the results would also tend to indicate that there is a problem with convergence. Another pillar of validation is stability. This is, numerical stability – there should be no point where the model calculates “impossible” things such as negative mass. Any model that creates such things fails validation. Several climate models use code that WOULD produce such impossible things, except that they have added additional code to “constrain” the values to realistic numbers. Many also produce a “singularity”, or numreical instability, at the north pole as they try to simulate oceans. The “fix” for this problem has traditionally been not to re-write the code so it doesn’t stumble at this point, but rather to put an island at the north pole – no ocean there, so no singularity, it’s all good, right? Another kludge. Another validation failure point.
OK, well what about verification? Of course, any model that fails validation cannot possibly even be considered for verification in the world of engineering, where responsability is squarely and legally on the shoulders of the engineer who signs her name to it, but we can look anyway, right? Sure, why not – we won’t be sure that there’s nothing wrong and we might get it right by good luck rather than good management, right? Oh dear – as Lucia has shown, the model predictions as stated by IPCC in 2000 failed to predict global mean surface temperature at the 95% confidence interval for the years 2001-2008. And while it’s certainly true that this might be reversed in the future as more data becomes available, it doesn’t look good, especially in light of the already failed validation, and even more so given that the more years that pass, the further away from reality the models seem to stray.
So, what does this all mean? It means that unverified and unvalidated models are being used in trillion dollar public policy. We are holding these models to a much lower standard than those we use for mere million dollar projects such as building bridges, designing cars and so on. What is wrong with this picture? Perhaps you might be thinking that this is breathtaking news. And indeed it would be – some might even say should be – except that this has been well known in the field of climate science for at least two decades. No-one cares. Anyone that wants to make an issue of it is derided as a “denier” – wow, what a surprise, huh? Bet you never saw that coming. I even asked CSIRO if they had done verification and validation studies – the meaningless reply they sent me was answered with the statement that they should publish their convergence study as no-one has ever done so before, and could they please point me to where I might find details. Are you surprised that they never answered me? Are you surprised that people who live and die by the number of published papers they have didn’t and still haven’t published a paper on this? No, I wasn’t either.
None of this means that climate models are useless or should be tossed away – they are a useful tool for learning about the way climate MIGHT behave under different circumstances. They are a good research tool and I fully support their development and use as a tool to aid understanding. What they are NOT is a useful tool for predicting future climate states of the real world.
Finally, I would ask that you remember this lesson when next you hear about the results of a climate model, or based on the output of such models, showing that things are “worse than we thought”. Focus on the part that says “… if these projections are accurate…” or similar and ask yourself: can I trust these models? The answer must surely be: not yet.
10
Niel,
Well done and well said.
Unfortunately most people seem to trust whatever they see that comes from a computer. I am sure that if they knew what we know they would be far more skeptical.
I remember a few years ago having a lively discussion with a relative on this exact matter. What it came to was that he trusted the models and I did not. He trusted that the Boffins creating the model would not have done anything untoward, I, of course was more sceptical.
Definitely if research conclusions are being derived from implementations such as the CRU models, then I’m sorry I cannot trust anything the scientific community comes up with unless I have had a chance to look at the code. Just like I need confidence that when I buy an electronic device that it has been through UL verification so it doesn’t catch fire, I need confidence that the processing of the data into information is valid.
So what would the answer be – D0178B compliance for Software used in Climate research?
I guess this is the sort of discussion that really has to take place wihtin the scientific community. The Scientific method came long before Fortran, after all.
10
Lionell et al,
So what is the solution to the problem?
After spending a lot of time and money inventing the Ada language which was supposed to enforce good standards, the Defense Department found that contractors were unwilling to use it because it was so full of picky details and red-tape. Programmers were bogged down in little details and couldn’t make progress at a realistic pace. So waivers were granted to allow C++ instead. After doing a little bit of Ada programming myself I can understand why.
The lesson from Ada seems clear; a language by itself can’t solve the problem. Even if you get rid of the worst offenses of C and C++ you haven’t solved the problem.
10
Roy Hogue: So what is the solution to the problem?
THAT is the ten trillion dollar question. I don’t think there is “the answer”. That is an answer that produces good results without knowledge, understanding, thought, discipline, or effort. Its a process, an attitude, a work ethic, an environment conducive to delivering a good product, and something that the individual brings to the table. Languages, operating systems, standards and practice manuals, management, and work environment. no matter how good, cannot work well without that individual quality being present.
It is well known that there is a huge difference in performance among individual developers. Sometimes it’s by many multiples of ten. This is true even when the same tools are used in the same work environment. The difference MUST be something within the person. Competency and ability are only part of the answer. Its what you do with what you have that makes the most difference.
My experience says its holding the right basic principles, having the right focus, having demanding personal standards, constant learning, constant improvement, intellectual honesty, intellectual integrity, and, most important, the self discipline to do the right things the best way you know how. Then do it better the next time. I can describe in some detail all of the things I do and I might even be able to teach them except for one thing: I don’t know how to teach the honesty, integrity, and self discipline to do it. THAT has to come with the person.
There are many factors that inhibit even the best of us from performing at our best. However, I believe they are only effective in the range of factors of two or three. I repeat, its not what comes from the outside that makes the big differences. Its what is inside the individual developer that makes the most difference.
10
Roy,
The answer is to have more eyeballs scrutinize the code and data. The open source model is pretty good for this and I would suggest that as a necessary part of the peer review process, all related code and data should be licensed under the GNU GPL or some other public license. Look what this has done for operating systems (I know you will object Lionell …). Linux is far more secure than any of Redmond’s variants of windows. The reason is that security through open disclosure is far more effective than security through obscurity. You can’t hide security flaws behind unpublished source code. Either, a) the flaky code is inadvertently released or b) some hacker with time on their hands stumbles upon the flaw.
George
10
co2isnotevil: I know you will object Lionell …
I do and very strongly. Case in point. There were a large number of eyes looking at the IPCC reports. The CRU “scientific” papers were “peer reviewed”. The fraud occurred anyway. That was largely because the minds behind the eyes were as corrupt as the so called climate science they produced. In the QC business, it has long been a rule of thumb that a 100% visual inspection is at best 80% reliable and that is for simple visual product defects and for honest inspectors. The bottom line is that there is nothing that is simple in software. The amazing thing is that some of it actually does work.
However, I have even a more fundamental objection to the GNU GPL concept. It is a gross violation of the concept of intellectual property. In fact it is the stated intent of its creators to define intellectual property into oblivion.
Now, I have no problem with your giving away your life’s work. You apparently know what its worth and its your choice to do it. Yet you advocate the ONLY valid model is that anyone who does software must do it that way too. Meaning that you believe you have the right to force them to stand and deliver their life’s work in exchange for what? Code written by a bunch of rank amateurs, just for fun. They generally produced code not worth stealing. The Linux hype notwithstanding.
I value my life’s work far more highly than that. In fact, a major portion of it is protected not only by copyright but also over ten US and international patents. I am not going to give that away. Any “free” code that comes into contact with my code, I carefully verify that it is in the public domain and that I have an unlimited right to copy, use, and modify. This is important, it is WITHOUT having to give away trade secrets, methods, procedures, concepts, and code that took me thirty years to develop in total. Pay me my price, and you can have it. Free? You must be joking. I will burn the code and its documentation first.
Finally, your security claim is bogus. You are comparing the discovery of issues with hundreds of millions of windows installations over two decades used by non computer people with at most a decade of a few hundred thousand systems used by computer geeks. In almost ALL cases, the primary security breach is due to the creature sitting in front of the computer and not the computer system itself. I have been using and programming computers for over 40 years and I have only caught two viruses. Only one of which required me to rebuild my system. The other virus installed but could not execute because I was running Windows NT and not Windows 95.
Finally, in my not so humble opinion, Linux is a pile of absolute garbage. Its poorly structure, poorly documented, and almost totally without support for the mere mortal user. Yes, I have looked at its source code. I wouldn’t touch it even if it were free. Wait, it is free. I guess that is how much it is really worth.
10
Lionell,
Your answer is pretty much what I would have said. However, if an organization has good project management, adopts and publishes its acceptable standards and conventions and then, as George suggests, reviews what’s being done frequently and enforces the standards, I think they have a better chance of success.
I was involved in a very large Fortran application and I saw first hand how much difference it made that management at several levels was constantly reviewing everyone’s work. They were aware very early of what parts of it were going well and what parts were not. The programmers who were not handling it either shaped up or were gotten rid of. After finishing my original assignment I was given what someone else had made a mess of to clean up and finish. The difference between what I had done and what I was handed was stunning. At that time serious belief that there should be design and coding standards was not widespread. But I had learned the hard way that “spaghetti code” was a nightmare and had begun to think about and practice better organization in self defense.
The project finished on time and within budget. We had quite a celebration when the DOD customer bought off on it. Not very many projects back then had such a glorious ending.
But the basic truth is as you said; the individual must have the conviction necessary to get it right.
10
Roy,
Yes, the right environment, the right management, and a few right people have a much better chance of success than the usual situation. Especially back in the DOD Fortran era.
No matter how many marketing pitches, no matter how many management initiatives, no matter how many process conferences, no matter how many consultants visit, there is no such thing as a software development silver bullet, never has been, and never will be. That won’t stop the endless search and the spending of billions to find one.
What management who seeks a silver bullet can’t accept is that the ONLY decision they can make with any effectiveness is go, no go, continue, or kill. Other than that, all they can do is make sure the objective continues to make business sense and that the waste baskets and bathrooms are kept clean. Anything else they can do will only affect the tattered edges – usually in a negative way. Once the objective is set, the rest is totally determined. Decisions are irrelevant at best. Its discovery that is required and management never has been good at discovery.
10
Peace! I’m no fan of modern development methodologies. When you adopt those you’ve made a decision to abdicate the management responsibility in favor of the silver bullet.
We agree. There ain’t no such thing.
10
Lionell,
Nice case against open source and all the nonsense that goes with it.
10
Lionell,
Yes, many eyes were on the IPCC reports and many of those eyes concluded that the reports were crap. Of course, the proof they were crap was buried behind a facade of protecting intellectual property as those who wrote the reports buried the objectors with self righteous indignation.
I have no problems with hiding proprietary software or data to protect patent pending technology. When you publish a scientific paper, or publish a patent, everything that went in to that paper or patent becomes public domain. What you get from a scientific paper is being first to figure something out that will advance the cause of science. What you get from a patent is an exclusive opportunity to turn what you figured out into money. SW is more like writing anyway, in that it’s covered by copyright laws in addition to patent protection, so you can always disclose source and maintain your IP rights without a patent. What’s the purpose of publishing a book if you only disclose the ending?
Hiding behind intellectual property protections to avoid disclosing the messy way that conclusions were driven, especially when those conclusions precipitate follow on conclusions which have world wide trillion dollar policy impacts, mustn’t be tolerated, although it’s acceptable to keep data and methods secret until publication, once published, that veil must be lifted.
Relative to open source, where it’s most important is for the infrastructure, cryptography and that which depends on cryptography like authentication and encryption. But beyond that, people have figured out how to make money in an open source environment anyway. What I don’t like about the closed M$ model, is that my IP depends on theirs, over which I have no control. For example, if I write code targeted exclusively to VC, which is what their user documentation guides you in to doing, that code is worthless without the VC compiler and proprietary M$ libraries, which I must forever buy from them as new versions supersede old ones.
George
10
co2isnotevil,
If your IP depends upon third party software, then you don’t have IP worth protecting. Its nothing but a variation on an existing theme. It would be easy to work around even if it
were to get a patent. Copyright is more than adequate.
If you think creating software is similar to just writing, I question that you have created software of any significance. Writing does not have to be logical, self consistent, adhere to any natural or scientific principles, compiler rules, nor be consistent with the hardware it runs in. ALL it is, is a sequence of words on a page. It has no operational significance. If you write software that way, it won’t even compile let alone execute and do something useful. To say software is the same as writing is to identify by the irrelevant similarity that both use symbols.
On Intellectual Property protections:
The information in a patent is not public domain until the term of the patent expires. Until that time, its FYI only and not for commercial use except by the terms of the patent holder.
The weakness of Copyright is that it does not protect specific new and useful inventions, methods, or applications of general principles. It only protects the specific expression of them.
Intellectual property needs all four levels of protection: Trade secrets, Trademarks, Copyrights, And Patents. Intellectual property comes into existence in EXACTLY the same way real property ownership comes into existence. One or more individuals expended their time, thought, and energy (their lives) producing the ideas and wealth to CREATE the values to EARN the property. They have a RIGHT to the product of their lives and no one else has that right. Especially and particularly anyone who did NOT earn it. Including the bleeping politicians.
On proprietary OS’s:
I have software that I developed over 20 years ago that is still part of my present software package. Some if it developed for Unix, MS Dos, and even the early versions of Windows. My current software runs on Windows 2000, XP, Vista, and 7. The newer OS’s give me access to capabilities the older ones don’t. The way you do that is to stay with baseline standards, design carefully, and implement cleanly. You do not adapt every new framework or initiative MS tries to push on the development community. MFC, COM, DCOM, .NET, managed code et. al. are generally bug filled crap not worth considering. They are nothing but fire and motion from Microsoft to keep the developer base off balance.
As a consequence, I have tight, clean, robust, and fast code that ports easily to new versions of Windows. Which, by the way is the only OS that I can get the performance and ease of development I need and at the same time get to keep control over my code base. There is no dialect of Unix/Linux that can offer me what I need. Apple OS/X doesn’t even come close. A few hundred dollars for the Windows added to new hardware is a pittance to pay for all that I get.
I was able to provide customers with reliable real time software for instrumentation and data reduction on Windows 3.1. Again, its a matter of dong the right things in the right way. What is right is dependent upon the tools you have to work with and the task you must perform.
10
Lionell,
There are over 500K lines of SW that I’ve developed and managed the development of, mostly related to silicon, including logic and timing simulation tools, layout synthesis and verification tools and a whole lot more, much of which I own IP rights to. The only compiler I use is gcc, because, like you say, it’s good to have portable code. I build on top of a set of open API, multi-sourced run-time libraries (i.e. libc, libm, …), rather than single sourced M$ dlls. The minute you include “windows.h”, the code is no longer portable, yet even most of the sys/xxx include files are common among the various different versions of Linux, Solaris, Mac and other Unix based OS’s. None the less, part of what I have is a portability layer that encapsulates potentially non portable requirements, which was required for compatibility with DOS and it’s successors.
You or I can write nice tight code if nobody else is in the loop, but to get more than one self interested entity to cooperate with each other and construct reasonably tight, clean code, requires well defined interfaces and open standards. This is why there needs to be some kind of distribution nexus based on the open source model for climate related code and data, which should include libraries of open source procedures for reading data files, managing the data as a gridded system, and manipulating it.
I recently wrote some super fast code to perform atmospheric absorption calculations based on HITRAN specifications of absorption lines (Lorentz integration with some bookkeeping). You can trade off compute speed for accuracy, but even at max accuracy, it’s faster than anything else I’ve seen, primarily due to using logarithmic, rather than linear, wavenumber buckets. I would have no problem contributing something like this, as long as it’s referenced when used (i.e. cited). In this sense, publishing a scientific software algorithm, is like publishing a scientific paper, with the same goal of advancing the state of science.
George
10
Sorry for the off-topic.
All the people involved in the GNU project (and other GPL projects) do so of personal choice. Although slanderers are out there trying to make out that GPL projects steal from proprietary codebases, no one has found a single item of proof. The famous SCO Group attempted to accuse IBM and got their backside handed to them with a cherry on top.
From industry experience I’ve found that GPL programmers are ten times more scrupulous and detailed about following intellectual property law to the exact letter. My experience from a number of shops that avoid GPL software in favour of various proprietary packages, is that such people are very willing to make a few extra “backup” copies that just happen to be used on additional machines, or other similar activities. I challenge you to find any GPL advocacy website that also advocates piracy of proprietary packages. If you find one, I can probably get them to change their story.
You might want to research Harald Welte’s work tracking down GPL violations to find out just how many proprietary products have illegally “borrowed” bits of GPL code in violation of the license. These are the people you should be pointing finger at in terms of a “gross violation of the concept of intellectual property”.
As a person who strongly advocates OpenOffice in the business workplace, I find it damn difficult to offer price as an incentive when potential customers for my services will just download Microsoft Office from a warez site and argue that the price of either package is the same. Piracy is just as bad for my business as it is for proprietary vendors.
I’m not giving any work away, nor are any GPL programmers, nor was that ever the intention. We offer GPL work as a licensed work under well defined license terms. You don’t have to like those license terms, they were not put there for you to like, they were put there to facilitate the exchange of software between like-minded people. You do not have to use GPL software, then you are more than welcome to do things your own way, as is your right in a free society. Just don’t expect other people to necessarily want to do things your way either.
Nothing in the GPL says “the ONLY valid model is that anyone who does software must do it that way too”. The GPL is a license that must be followed if you want to partake in copying, distributing and modifying GPL software. Other models are completely valid providing they do not attempt to mix incompatible licenses.
Maybe what you are really trying to say is that GPL reduces the value proposition in the artificial scarcity induced by proprietary software? In which case I feel no guilt for competing in a free market.
10
Lionell : “Finally, in my not so humble opinion, Linux is a pile of absolute garbage. Its poorly structure, poorly documented, and almost totally without support for the mere mortal user.”
The ‘net would be a lot less interesting and reliable without Linux, but I guess that doesn’t address your concern with the “mere mortal” users. 😉 And I’d disagree significantly WRT documentation – linux is much more documented than Windoze. I suppose you could spend a fortune getting all the information you need to tie down a Wintel box to a decent level of security, bit IMHO you can get a Lintel box to the same point without spending a cent on documentation (except your time and perhaps a ‘net connection).
To get back to my previous point a little…
It’s certainly possible to conduct software V&V – it happens all the time for mission-critical software in medical devices (as diverse as pacemakers and ECG analysis) and many other areas such as aviation (fly-by-wire), automotive (ABS brakes) etc etc. Now granted, these systems are typically significantly less complex than most climate models, however if we are making changes that affect every human on the planet – how they live, where they live etc etc – then surely we have the right to ask for at least the equal to other mission-critical software. Yes it costs – and quite significantly too. But we are talking about fractions of a percent of what we are considering spending based on the results of this software. It sure seems like a no-brainer to me that we spend a small amount up front to make sure we’ve crossed all the “T”‘s and dotted all the “I”‘s – even if it’s not perfect (and it won’t be), we’ll be significantly closer to perfection than we are now. Don’t forget that we are talking about making legally binding international agreements that we can not “back out” of easily once we sign, and I for one am not happy about making such commitments based on proprietary software written by non-profession software developers with no V&V.
10
co2isnotevil:
Did you write the code for captive use or for commercial sale?
That is what separates the issues. If its for captive use, you don’t care if its GPL because you don’t have to give away your intellectual property. You don’t really have to care about much of anything but making your few local users happy. You get paid no matter what. The instant you distribute it for sale or just outside your captive situation, you have to give the source to anyone who asks for it. The individuals you must give it to must also give it to anyone who asks. This negates the possibility of ever selling it again.
I make my living by creating and selling very valuable and very unique intellectual property. If I have to give it away, I am no longer able to make a living. That is except as a low wage help line technician for the product I spent 30 years creating. Like I said, I will burn it before I will be forced to give it away.
10
Tel,
Don’t worry, I wouldn’t touch GPL code with a 1000 meter pole.
As for your artificial scarcity crap, my intellectual property would not have existed if it were not for the work I have done and the years I prepared to be able to do it. I have a RIGHT to profit from my efforts.
My work product is scarce because no one else has done it and there is only ONE me. THAT is not artificial. Its simply a fact. There are a large number of so called high level professionals in the field who say what I have done is impossible or that I have done it in such a way they have proved it doesn’t work. Yet it works. And it works a damn sight better than anything they have ever done!
If you say that by copying my work you are not taking it from me, that is bullshit. You would be using the results of a significant portion of my life without my permission and without paying for it. THAT is theft AND making me your slave.
Do your thing and give your work away. Its your choice. I won’t do it.
10
co2isnotevil,
There is very good reason why the patent laws were written to specifically exclude scientific discovery. Laws of physics cannot be patented, mathematical theorems cannot be patented. The patent system was originally designed for industrial processes, i.e. application of general knowledge to a particular commercial undertaking.
Patents are a tradeoff between the public good (i.e. moving technology forward and gradual growth of the public domain) and private incentive (property rights that encourage an individual to strive for excellence). With all tradeoffs there’s a balance and the patent system has gradually shifted that balance away from the public good and towards the private individual (patent terms have gotten longer, totally obvious patents are still approved, patent holders are given extraordinary benefit of the doubt when prior art is presented, etc). Most of this has been the USA, with the rest of the world somewhat dragged along.
Software is a sticky point, it is a bit like mathematics, and a bit like an industrial process. Actually it is a bit like a lot of things, and has no easy analogy in the physical world. Arguments for and against software patents are filling other blogs around the world, it is far too complex to even start covering all the legal precedents, the real world examples and the political sentiments. Needless to say, opinions on the matter of software patents vary greatly.
10
No you have no such right, regardless of how you might like to kid yourself.
You have a right to attempt to profit from your efforts. No one has a right to any particular return on investment, never have done, never will do. The free market offers only the guarantee that you get fair chance to offer your wares shoulder to shoulder with others offering similar wares. The outcome is entirely a matter of customer choice and value proposition.
I’ll draw your attention to the US Constitution (which you seem to respect):
Note well: pursuit of happiness, no guarantee of outcome.
10
If you care to take a bit of trouble reading what I actually said, you might note that the proprietary software world thieves a whole lot more from the GPL world than happens the other way around. Although I know nothing about your particular work, statistically over the whole industry no one has found one single place where a GPL code has stolen from a proprietary code. Not one.
10
Neil,
I have no problem with “tying down windows” for a “decent level of security”. I have done it since Windows 3.0. I am doing it right now with Windows 7. Like I said, the overwhelming cause of security problem is the component between the keyboard and the chair seat.
Secondly, there is documentation and then there is documentation. Unix quality MAN pages are an absolute joke. I know because I have used at least four dialects of Unix since 1983 to 1995 inclusive. Having to study the Linux source code to find out how things work is worse than a joke. The rest of the Linux documentation follows the Unix standard.
Agreed, software V&V is done all the time. All that does is test that it meets the written specifications. If there is a bug in your specification, you are hosed. Often that is where the most serious bugs breed.
You cannot test quality into software. It has to be designed in. Also, you cannot possibly test every permutation and combination of input and environmental condition of anything but a trivial program. ALL you can do is test classes and known error limits. You cannot catch them all. Especially the unknown error limits. Further, you don’t find all the wondrous and magical ways real live uses will find to break your code. Users don’t pay attention to your specifications or your documentation. They pay attention to what they need to do and try to figure out how to get it done.
I have written code for life critical medical devices. The VP of product development told me 5 years after I left the place that he didn’t know how he could have delivered the stream of products he did without the work I left behind. It was a general purpose graphical user interface on top of VX-Works. Linux would not have had a chance in hell of being applied because it does not understand the needs of a high reliability, highly responsive real time application. Its idea of real time, is time of day to within a few 100 milliseconds more or less.
10
I think this is more than enough.
10
Sorry for starting the OT, but I still think it makes sense as a fair way to share climate data and models.
Lionell: I’ve developed SW for captive use, commercial use, and have done all kinds of licensing arraignments. Just because you put some things into a public license doesn’t necessarily mean that you put everything into it. If the last time you looked at Unix was 1995. you’re missing a lot of context. Out of the box, open UNIX’s like Solaris and Linux are so incredibly fully functional and trivially upgradeable. They offer the features of the highest level of functionality offered by M$ with all the trimmings, and then some, and it even includes client and server level M$ compatibility. They transparently interoperate with each other and other unix’s and even M$ clients and servers. I also use OpenOffice and I really consider it a superset of M$ office. It was a little rough at first, primarily because the M$ proprietary file formats had to be reverse engineered, but it’s come a long way. One of the reasons I like open software is that it evolves far more quickly than closed software.
George
10
The code above was “Commented out” meaning inactive in it’s current form. It also has no context, so we can’t be sure it was ever used. Having said that, it was created for some reason, we don’t know what that was, and since the Team have thrown away the data, only a fool would trust them with a smoking gun.
There are useful comments on Eric Raymond blog and on Watts Up. (Copied a few here).
Eric Raymond, a guru blogger of programmers and of the open source movement exposed this code on Nov 24. .
I’m told he had not commented on climate change in his years of blogging before this point. But it’s clear now, he had been watching and knew exactly what to look for.
Anthony, I’m sure Eric has been reading Watts Up and CA! (look at how well he knows the terms of engagement…)
Eric (ESR) responds to questions on his site.
———-
“>The “blatant data cooking” is to use the actual thermometer data where it’s available, which, of course, shows no decline over those decades …
esr: Oh? “Apply a VERY ARTIFICAL correction for decline!!”
That’s a misspelling of “artificial”, for those of you slow on the uptake. As in, “unconnected to any f…. data at all”. As in “pulled out of someone’s ass”. You’re arguing against the programmer’s own description, fool!
In fact, I’m quite familiar with the “divergence problem”. If AGW were science rather than a chiliastic religion, it would be treated as evidence that the theory is broken.”
——
“>The program you are puzzling over was used to produce a nice smooth curve for a nice clean piece of COVER ART.
esr: Supposing we accept your premise, it is not even remotely clear how that makes it OK to cook the data. They lied to everyone who saw that graphic.”
——
“>I’m sure we’ll see a correction or retraction here any minute.
esr: As other have repeatedly pointed out, that code was written to be used for some kind of presentation that was false. The fact that the deceptive parts are commented out now does not change that at all.
It might get them off the hook if we knew — for certain — that it had never been shown to anyone who didn’t know beforehand how the data was cooked and why. But since these peiple have conveniently lost or destroyed primary datasets and evaded FOIA requests, they don’t deserve the benefit of that doubt. We already know there’s a pattern of evasion and probable cause for criminal conspiracy charges from their own words.”
—————————————————-
JohnSpace wrote:Watts UP:
For those saying that this isn’t a “smoking gun” because we don’t know how it has been used, you are right as far as that goes, however you are wrong for a more serious reason. No one knows how this model was used. That is the whole point. These scientists would not turn over how the made the model and what their assumptions were based upon. They lost their data, their models were spaghetti, and they increasingly lost control over the process. I don’t care whether this was fraud or incompetency, it sure as heck isn’t science, and it most assuredly should not have been used to justify billions of expenses.
This is a “smoking gun” because even the scientists who MADE this code can explain it and whether or not it was used. As such all their work is now suspect.
JJ wrote on Watts UP:
Incidently, for those of you who think ‘It was commented out!’ is some sort of definitive resolution to this issue – It Aint. When we programmers ‘comment out’ code like that, we do it so that we can comment it right back in if we want. If we have no intention of ever running that code again, we dont comment it out. We delete it. That the code was commented out is no proof whatsoever that it was never used.
We need to know what this code does, what the data in it represent, to which data it was applied, what the results were, and how the results were used. Absent that, this is just an interesting lead that needs to be followed. Pretending otherwise is hypocritical, and can backfire in ways that could be used to smokescreen the objects of legitimate criticism that we are seeing in the whistleblowers data.
10
After all is said and done they had a clear interest in making their data show something it simply didn’t show. We have found the comment and code that proves they modified data to meet their preconceived specs. What more do we need? This little bit of code convicts them. Any explanation they give will be very hard to swallow. I would argue that the purpose was to deceive or as one comment on Eric Raymond’s blog said, that it was to see if their cooked data would look reasonable compared with the real stuff and yet still show what they wanted it to show (not the exact quote). Any way you look at this they were trying to deceive the outside world as we have believed all along.
It will all be put under a microscope. Some will be honest about it and others will not. In the meantime this is a high stakes game with vested interests in making money, including the high priest of the Church of CO2 is Evil, Al Gore. Climate change is really a political disease, not a science problem. We have to beat down any agreement in Copenhagen. A united effort to get it out that the data was phony and there was no evidence that CO2 is doing anything is what we need right now.
10
co2isnotevil,
Its the standard refrain: “the next version will be better”; “you are using the wrong version”, “you should have used version X”. I don’t care if your base line is 1970, 1990, or 2009. Where is the version that “just works”. Meaning, does what it is reported to do, does it in a way that you need it to do it, does it without having to jump through hoops, does it without having to spend ages reconfiguring it, ie Just Works. It does not exist. Some are better than others. None are the silver bullet that can solve all problems, without a problem, forever, amen.
That being said, I have used Windows deeply since 3.0. I jumped on Windows NT as a beta tester in 1992. I have made 32 bit Windows do things that others think impossible. It is hands down the most powerful most flexible most adaptable workstation operating system out there. Unix in ANY of its incarnations is an amateur hack job by comparison and has been from its inception.
I am done with this conversation.
10
Does anybody know where to find the full source code? Hard to judge anything accurately with several lines of code.
10
Comments in code like this are, of course, unhelpful, but this is all entirely irrelevant until you have asked the programmer concerned how the array “valadj” was arrived at.
Were the numbers hand picked?
Or are they simply hand-copied from another piece of code that produced them from a statistical treatment?
Until you can answer this question, your expressed opinion is entirely inadmissable of any accusation of wrongdoing.
10
Good post I just like it, Keep adding more Photoshop Tutorials like this!
10